Abbiamo l'abitudine di scaricare vari file o contenuti dal web. Inoltre, trasferiamo continuamente file sui nostri computer. Di conseguenza, avremmo numerosi file duplicati nel nostro sistema senza accorgercene. È comune trovare lo stesso file sull'unità di archiviazione in directory diverse o eseguire il backup di alcuni file in più posizioni, oppure potresti avere file duplicati con nomi diversi ma lo stesso contenuto.
I file duplicati sono principalmente uno spreco di spazio di archiviazione. Occupano una notevole quantità di spazio di archiviazione e possono portare a una carenza di spazio di archiviazione del sistema. Pertanto, è essenziale individuare ed evitare che i file duplicati occupino troppo spazio. Questo articolo ti guiderà attraverso i modi migliori per trovare i file duplicati e rimuoverli.
![trova file duplicati in Linux]()
Come vengono generati file duplicati nel tuo sistema Linux
I file duplicati sono copie identiche dei file originali archiviati o installati sul tuo sistema Linux. Vari motivi possono far sì che questi file appaiano legittimamente sul tuo sistema. Esistono molti tipi di file duplicati contenenti documenti, audio, video, immagini e file eseguibili. Troppi file ridondanti in un sistema Linux possono danneggiarne le prestazioni complessive.
Potresti riscontrare diversi problemi su Linux causati da file duplicati. Avere file duplicati può aumentare significativamente il carico su Linux. Di conseguenza, le prestazioni e la funzionalità potrebbero risentirne a causa di file disordinati.
Di seguito sono riportati alcuni modi in cui i file duplicati possono apparire su Linux:
- Download multipli dello stesso file senza esserne consapevoli lasciano molto spazio per la formazione di file duplicati.
- Quando si trasferiscono file tra Linux e Windows, è possibile importare lo stesso file più di una volta, con conseguente duplicazione dei file.
- Avere backup di un file specifico in varie posizioni può anche generare più copie.
![articoli Correlati]()
Cercatore di file duplicati Windows 11
Stai cercando il miglior cercatore di file duplicati? Se non hai ancora idea di come rimuovere i file duplicati in Windows 11, leggi questo post per risolvere il tuo problema.
Perché dovresti rimuovere i file duplicati su Linux
Devi assicurarti che tutti i file inutili siano tenuti fuori dal tuo sistema Linux affinché continui a funzionare senza intoppi. Puoi trovare e rimuovere i file duplicati in modo sicuro su Linux usando diversi metodi. È possibile utilizzare questi metodi per mantenere il sistema aggiornato e privo di ingombri.
Oltre a migliorare le prestazioni di Linux, la rimozione dei file duplicati libera anche molto spazio di archiviazione cancellando innumerevoli file non necessari. Ottieni i seguenti vantaggi rimuovendo i file duplicati su Linux:
- Consenti a Linux di funzionare in modo efficace ed efficiente senza problemi di ritardo.
- Libera molto spazio di archiviazione, che può essere molto utile.
- Organizza sistematicamente i file per evitare un accumulo di file.
- Ottimizza l'ordinamento dei file, riduci i rallentamenti e accelera la produttività.
Come trovare ed eliminare i file duplicati di Linux
Trovare e rimuovere i file duplicati diventa facile quando si utilizzano i seguenti metodi:
- Metodo 1. Trova i file duplicati per nome
- Metodo 2. Trova i file duplicati per dimensione
- Metodo 3. Trova i file duplicati con il checksum MD5
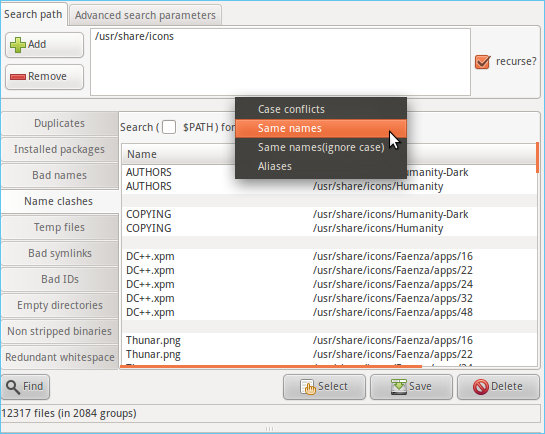
Metodo 1. Trova i file duplicati per nome
![trova i file per nome in Linux]()
Se non desideri utilizzare alcun cercatore di duplicati, trovi e rimuovi tutti i file duplicati cercando i loro nomi. Utilizzando i seguenti script, è possibile avviare il processo:
Passaggio 1. Segui e scrivi lo script.
awk -F'/' '{
f = $NF
a[f] = f in a? a[f] RS $0 : $0
b[f]++ }
END{for(x in b)
se(b[x]>1)
printf "Nome file duplicato: %s\n%s\n",x,a[x] }'
L'esecuzione di questo script confronterà e mostrerà tutti i file con lo stesso nome.
Nota* Questo metodo è applicabile solo per trovare file duplicati con lo stesso nome. Non confronta i dati che contengono.
Passaggio 2. Assicurati che l'elenco mostri tutti i nomi dei file incluso il percorso in questo modo.
Nome file duplicato: textfile1
./folder3/textfile1
./folder2/textfile1
./folder1/textfile1
Nome file duplicato: textfile2
./folder3/textfile2
./folder2/textfile2
./folder1/textfile2
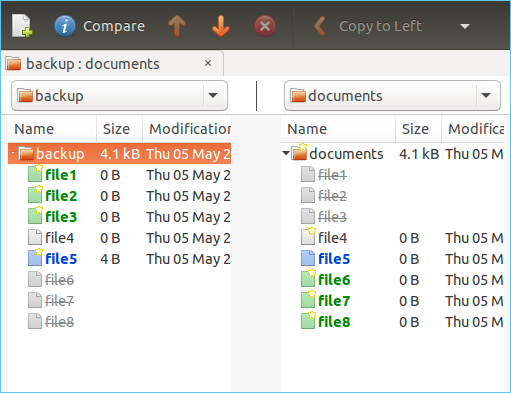
Metodo 2. Trova i file duplicati per dimensione
![cerca i file duplicati per dimensione su Linux]()
Questo metodo è un modo rapido per trovare duplicati con le stesse dimensioni. Verifichiamo come funziona:
Nota* Questo metodo è utile per i file della stessa dimensione in quanto non analizza il contenuto che hanno.
Passaggio 1. Scrivi lo script fornito per trovare i file con le stesse dimensioni.
awk '{
size = $1
a[size]=size in a ? a[size] RS $2 : $2
b[size]++ }
END{for(x in b)
if(b[x]>1)
printf "Duplicate Files By Size: %d Bytes\n%s\n",x,a[x] }' <(find . -type f -exec du -b {} +)
Nota* Questo metodo è utile per file di dimensioni simili in quanto non analizza i dati in essi contenuti.
- Il comando du nello script specificato si applica per calcolare le dimensioni del file.
- Il comando Trova accetta un parametro chiamato -exec du -b {} + per passare la dimensione del file al comando AWK.
Passaggio 2. Quando applichi lo script specificato, mostrerà l'output in questo modo:
File duplicati per dimensione: 20 byte
./folder3/textfile1
./folder2/textfile1
./folder1/textfile1
File duplicati per dimensione: 35 byte
./folder3/textfile2
./folder2/textfile2
./folder1/textfile2
Ora puoi individuare il percorso del file per trovare e rimuovere i duplicati.
Ecco i dettagli dello script in modo da poter vedere cosa fa.
- <(find . – type f) - Affinché AWK possa leggere l'output di find, dobbiamo utilizzare la sostituzione del processo.
- find . -type f - Questo comando esplora tutti i file nella directory searchPath.
- awk -F'/' - Usiamo '/' come variabile interna del comando AWK. In questo modo, puoi estrarre il nome del file più facilmente. Troverai quindi il nome del file nell'ultimo campo.
- f = $NF - La variabile f viene utilizzata per salvare il nome del file.
- a[f] = f in a? a[f] RS $0: $0 - Questo codice è utile se il nome del file non esiste. Creiamo l'accesso per mappare il percorso del file originale utilizzando questo codice di script.
- b[f]++ - Viene creato un altro array b[] per tenere traccia del numero di file con lo stesso nome.
- END{for(x in b) - Stiamo usando questo codice per analizzare tutte le voci nell'array b[]
- if(b[x]>1) - Se sono presenti più file con lo stesso nome di x, significa che ne sono state eseguite più copie.
- printf “Duplicate Filename: %s\n%s\n”,x,a[x] - Alla fine, questo codice usa per stampare il nome file duplicato x. Per stampare tutti i percorsi completi, incluso il nome del file, utilizziamo a[x].
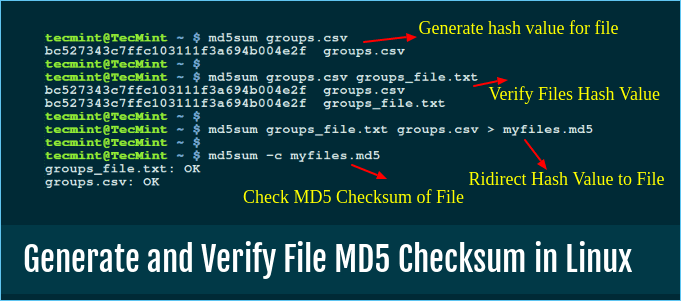
Metodo 3. Trova i file duplicati con il checksum MD5
Identificare i duplicati utilizzando il checksum md5 sarebbe la soluzione più gestibile per chiunque. Le persone usano questa funzione per individuare i file con lo stesso checksum. Inizialmente, il checksum MDS è progettato per verificare l'integrazione dei dati.
![generare e verificare il checksum del file md5 in Linux]()
Inoltre, puoi trovare file che probabilmente hanno lo stesso contenuto. Per navigare in un hash MD5 di un file, possiamo usare il comando md5sum in Linux.
Passaggio 1. Iniziamo utilizzando lo script fornito nella shell dei comandi:
awk '{
md5=$1
a[md5]=md5 in un ? a[md5] RS $ 2 : $ 2
b[md5]++ }
END{for(x in b)
se(b[x]>1)
printf "File duplicati (MD5:%s):\n%s\n",x,a[x] }'
- -exec md5sum {} + è il parametro aggiuntivo al comando find.
Passaggio 2. Quando si applica il comando fornito, verranno visualizzati i risultati come indicato di seguito:
File duplicati (MD5:1d65953b527afb4bd9bc0986fd0b9547):
./folder3/textfile1
./folder2/textfile1
./folder1/textfile1
Nel risultato, puoi vedere che abbiamo tre file che hanno lo stesso nome text-file-2 , ma l'hash MD5 non li trova poiché il loro contenuto è unico.
Guida aggiuntiva: identifica e rimuovi i file duplicati con semplici passaggi
Le persone possono incontrare il fastidio di file duplicati anche se utilizzano Linux o Windows. Sebbene i file duplicati non siano difficili da eliminare, possono essere fastidiosi da trovare ed eliminare. Scopriamo il metodo migliore per te:
Se sei un utente Windows, puoi anche eliminare il disordine evitato di file duplicati.
Correzione 1. Identifica e rimuovi mensilmente i file duplicati
Come abbiamo discusso nel caso di Linux, puoi anche identificare e rimuovere i file duplicati ordinandoli per nome o dimensione. Per trovare ed eliminare file duplicati in Windows, puoi aprire la cartella da cui desideri trovare i duplicati. Ora usa la funzione di ricerca in Esplora risorse, digita l'estensione del file e ordina tutti i file per nome o dimensione. In questo modo puoi identificare tutti i file con la stessa dimensione o nome.
Correzione 2. Identifica e rimuovi automaticamente i file duplicati
Trovare ed eliminare i file copiati è un processo lungo e problematico. Ti consigliamo di tenere le mani sul miglior cercatore di file duplicati che consente di risparmiare tempo e fatica allo stesso tempo. Pertanto, si consiglia di utilizzare EaseUS DupFiles Cleaner, famoso per le sue funzionalità avanzate e la facile usabilità.
EaseUS DupFiles Cleaner è adatto a tutte le unità di archiviazione interne ed esterne, comprese le unità USB e le schede SD. Il suo algoritmo avanzato è ideale per trovare tutti i tipi di file duplicati con una precisione del 100%.
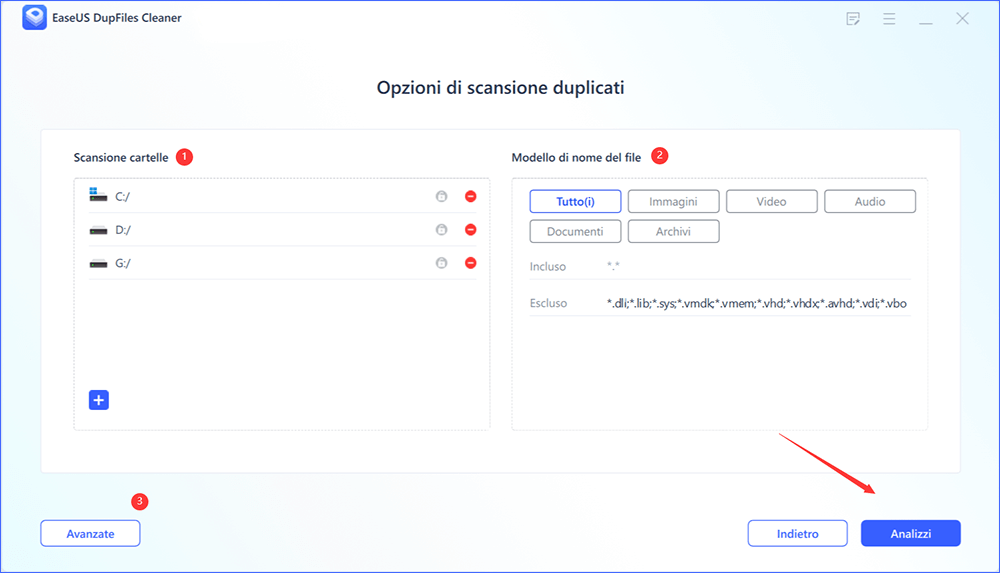
Ecco come puoi utilizzare questo software per cercare ed eliminare file duplicati su Windows:
Passaggio 1. Apri EaseUS Dupfiles Cleaner e fai clic su Scansiona ora per iniziare la pulizia. EaseUS Dupfiles Cleaner selezionerà automaticamente tutti i dati in tutte le partizioni. Puoi eliminare le partizioni che non desideri ripulire premendo il segno "-" in Scansiona Cartella e scegliere i tipi di file in Modello di nome del file.
* È possibile fare clic su Avanzate per personalizzare la scansione e il sistema attiverà la modalità di protezione dei file per impostazione predefinita.
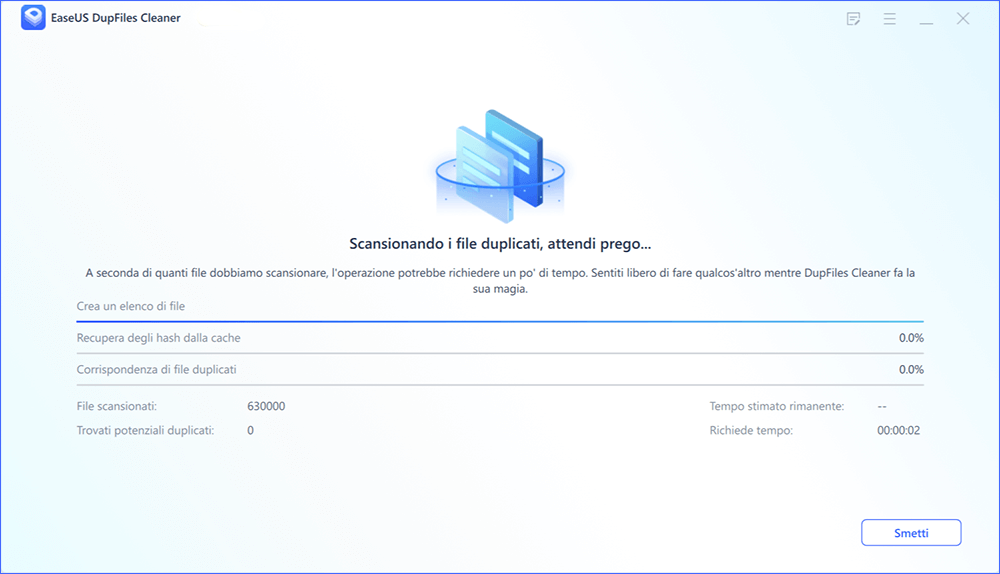
Passaggio 2. Inizia il processo di scansione, attendere pazientemente. Il tempo dipende da quanti file devi scansionare.
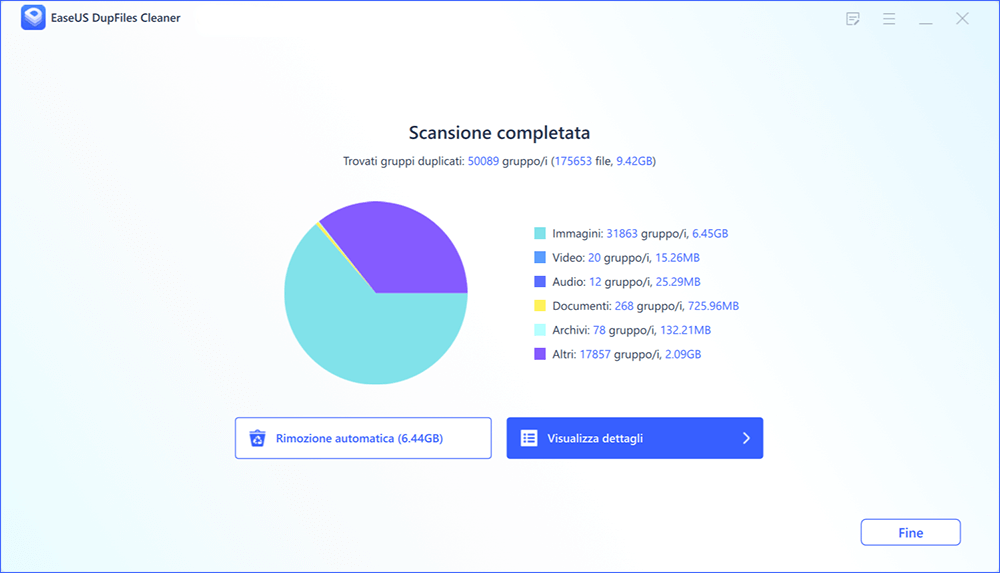
Passaggio 3. Al termine della scansione, è possibile fare clic su Rimozione automatica per ottenere una pulizia con un clic.
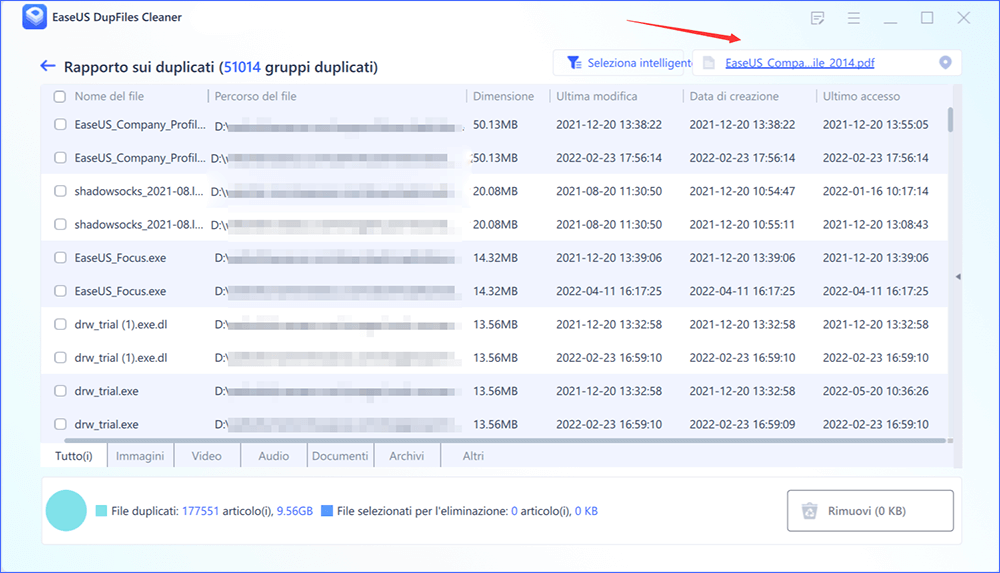
Passaggio 4. Se hai ancora dei dubbi, puoi scegliere di fare clic su Visualizza dettagli per avere un controllo.
* Puoi fare clic su Seleziona intelligente per controllare ulteriormente quale tipo di file devi ripulire e se non riesci a identificare il contenuto dal nome del file, puoi fare clic direttamente sul nome del file nell'angolo in alto a destra per visualizzarne l'anteprima.